Product Quality — Measure what Matters
A challenge often in front of senior leaders in engineering is to confront quality issues of the platform and product. In SaaS environments, it includes the service related interruptions. Every fast growing startup (more specifically, startups in enterprise space) goes through this challenge. The first step in addressing these issues is to decide what metrics to track and making it visible to the entire organization so that everyone can see through the data and resonate with why we have to change some of the practices. Tracking the right metrics is critical. How we balance the engineering bandwidth across new features/products, technical debt, production availability and addressing the defects is a different topic that I will write in another post. Quality is a mindset that needs to be owned by everyone in the organization — right from product teams capturing the customer use cases comprehensively, testing the use cases in pre-production environments before releasing, engineers following the best development practices (specs, unit/functional testing, code reviews, code coverage, static analysis and automation of these test cases), tech writers writing clear user facing docs and finally support teams knowing these features in and out.
At Harness, myself and Jyoti has decided early on to present these quality metrics in our bi-weekly all hands and also send a report of the current trends and progress to the entire organization. This level of transparency is key to gain the trust of everyone. These metrics and actions are reviewed in our weekly leadership meetings and also within the functional teams.
We started early on with analyzing the historical data and decided to track these 5 critical metrics to assess the quality of our platform and put an action plan to address any deficiencies.
- Customer Found Defects — these are the issues escaped our internal testing. Either customers are finding these defects and calling our support or these issues are found by our internal teams (support, sales engineering) outside of R&D
- Internal bug backlog — the backlog of bugs that are found in our own internal testing by developers and quality engineers in the sprint cycle. Some of them are addressed right in that cycle and some of them that are not perceived as critical goes into the backlog
- Resolution time and SLAs — SLAs are important for customer found defects and this metric tracks the resolution times — from when the issue is filed to when the fix goes into production
- Regressions — If there is one thing that frustrates your customers, it’s the regressions — something that was working for them till yesterday is now broken after a release. This is one of the big engineering nightmares— you can lose the trust of the customers quickly if we are not serious about addressing this with your teams
- Production Availability — while it’s important to track product functional issues, uptime metrics are very critical to keep our customers
As always — one thing I have learnt from my early days of running the platform at Zoom and delivering happiness — be honest about these metrics with your customers as well and have a solid plan to address them from day one.
Use these metrics as eye openers, to make right business decisions, to set the right goals, and to spread the awareness. Never use them to penalize your teams.
Customer Found Defects
The cost of a customer finding an issue and the engineering deliver a fix to production is significantly high compared to the same issue found in the development cycle. Every issue that is filed by our customers and other internal teams in Jira is tracked with a label to indicate that these issues are coming from the field. The initial triaging include:
- Making sure that this is a defect and not an enhancement (Bug vs Enhancement is a long running engineering debate in every org which I will write about in another post — at the end of the day, it doesn’t matter how we classify the issues as long as we deliver happiness to our customers but it does impact the way we address them)
- Assign a right priority (more on this in the SLA)
At the beginning of the fiscal year, we review our entire portfolio and set targets for each of the products on what would be an acceptable CFD number — the goal is not to ship a bug free product but rather improve the quality of the code/testing and minimize the leakage of critical issues. We analyze the data every single week, put them in different buckets and present a single graph which is not only easy to understand for everyone but also help to spot the areas that needs attention.

The goal here is to look for larger trends — if you stay in red or yellow zone for 3 consecutive weeks, it’s time to dig deeper and take some actions.
Internal Bug Backlog
While CFDs shows overall trend from the field, there needs to be focus on reducing the overall backlog of internally found defects. These defects are in the features that we have already shipped and they are potential CFDs — it’s just that we have decided not to prioritize fixing them before releasing the feature into production. At Harness, we review these backlogs at the beginning of every quarter and set a goal (in OKR) to fix them with bandwidth assigned. All these OKR’s are reviewed at the end of the quarter — either the teams end up accomplishing them or take the learning to the next quarter.
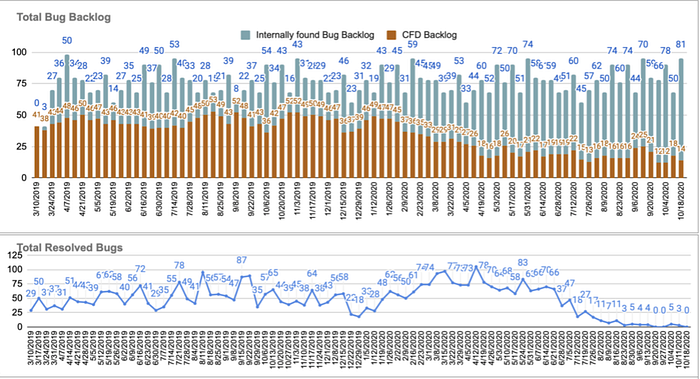
This chart gives us a rolling weekly trends of overall bug trends, the % of CFDs and the resolution rates. Setting clear quarterly goals for each of the product teams and assigning the bandwidth to address them is the key to reducing the backlog.
Resolution Times
We have adapted a model of setting 4 priorities to each of the reported issue — P0 being an production incident (resulting in outages or degradation of service) which triggers an incident response protocol, P1 issues are blocking customers, P2 and P3s are less severe and less impactful. But we have clear SLAs for each of these priorities and tracking if these SLAs are met is an important component of delivering happiness to our customers and field teams.

Again, look for larger trends and not individual data points. There are always cases where your team is waiting for a customer to respond with more logs or getting into bandwidth issues where there is more business focus to release a feature to unblock a deal or a customer. These delays will affect the SLAs on specific cases and there is not much you can do about it.
Regressions
Every team battles regressions unless you have done 100% automation of every single customer scenario. It’s important to consider every regression as an opportunity to educate your teams and also improve the automation. Automation is an investment — it’s a business decision.
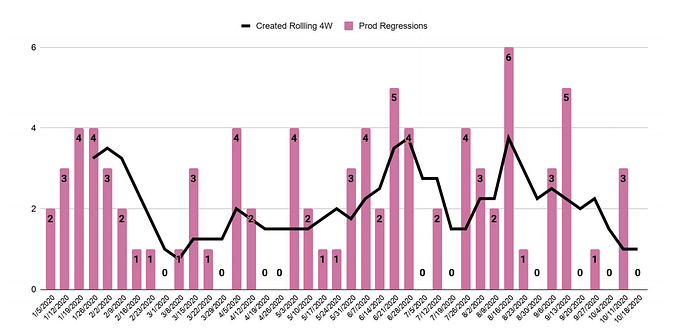
We take every single regression seriously — each one of them gets analyzed on where we could have caught it and if it’s missing automation, it gets added. There are scenarios where that particular case cannot be automated — then track them for manual testing and mark them as release gater.
Production Availability
We keep our SLAs and incidents completely transparent. Again, this is tracked in the same way we track other metrics. We establish clear quarterly goals and all of our teams strive to achieve them. Production stability is multi dimensional and involve cloud providers, infrastructure, networking, storage and other third party services we end up using and not just related to the product or platform.
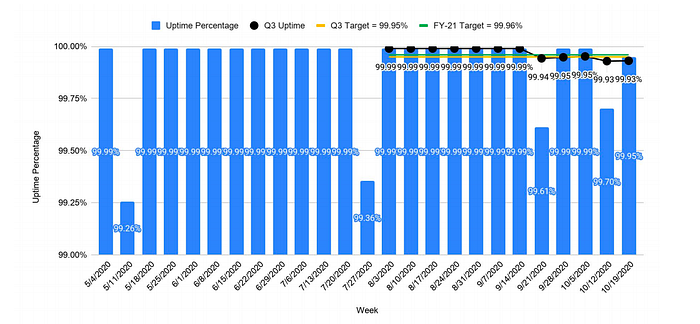
Service availability is another topic which I will cover in a follow up article.
Harness is a fast growing startup and an amazing place to work — Our platform is mission critical to our customers and we take that responsibility seriously. Our teams are solving complex computer science problems every single day. Check out our open positions in R&D — https://jobs.lever.co/harness?team=Engineering
